| 正则表达式+示例(以示例为主)新手小白都能学会的超详细简单教程讲解 | 您所在的位置:网站首页 › linux find 正则表达式例子 › 正则表达式+示例(以示例为主)新手小白都能学会的超详细简单教程讲解 |
正则表达式+示例(以示例为主)新手小白都能学会的超详细简单教程讲解
|
一:含义
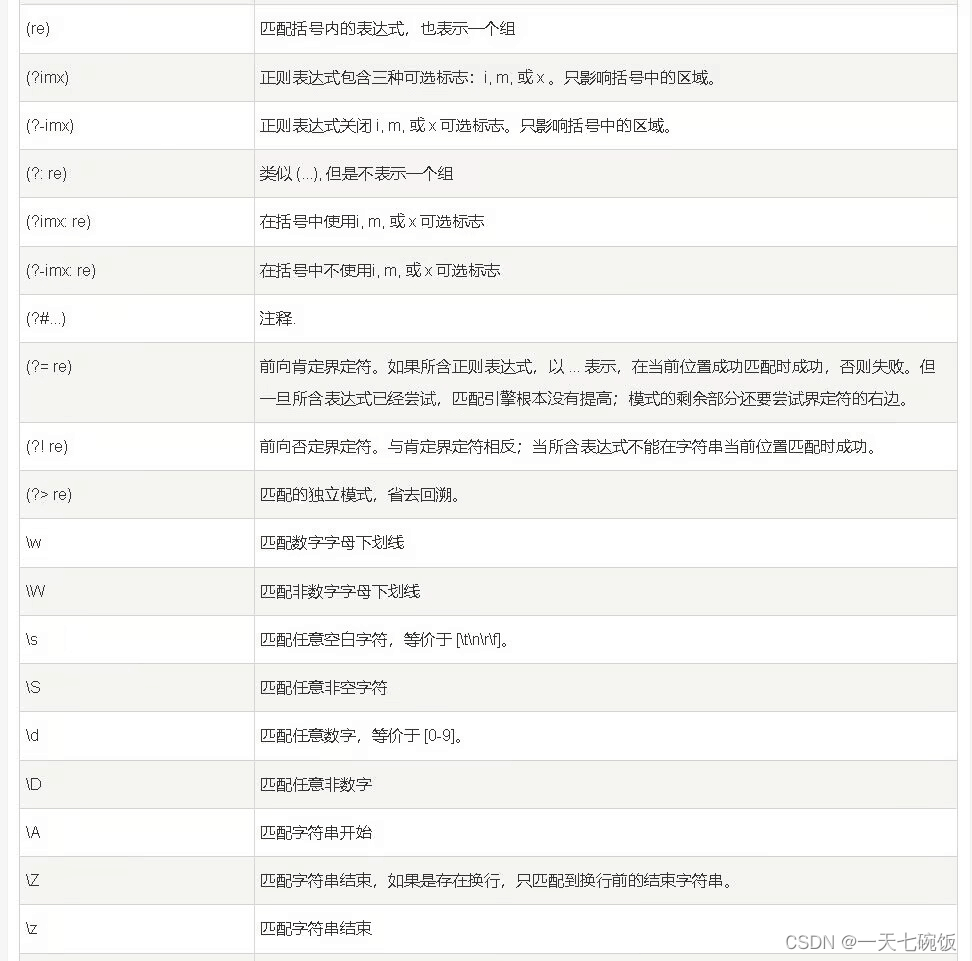
首先我们来了解一下正则表达式是什么 正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。它可以在文本中查找、替换、提取和验证特定的模式。 二:元字符有特定含义的字符,常见的有:
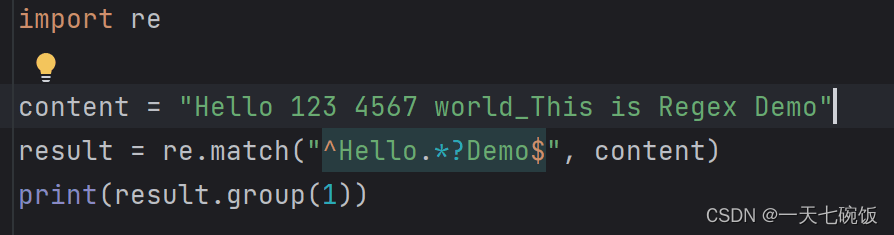
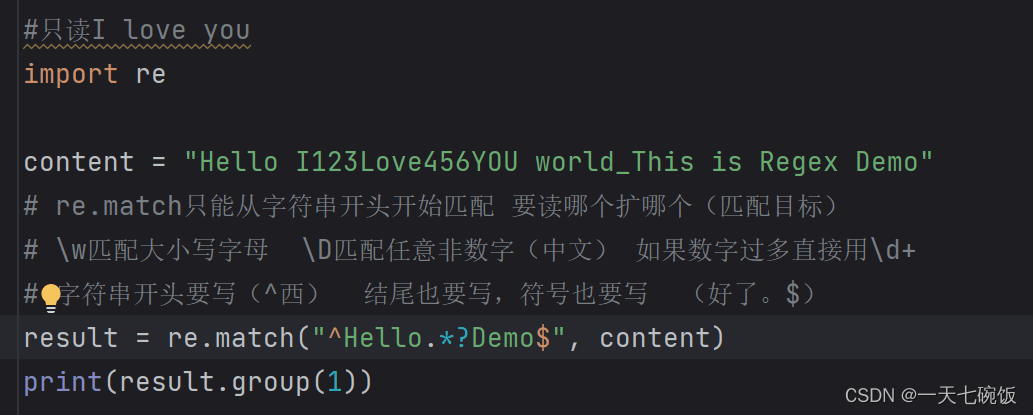
这里推荐菜鸟教程,里面有很完整的内容。正则表达式 – 教程 | 菜鸟教程 三:如何使用我们先以一段代码为例 (一)如何表示空格与数字为例: 1. 导包注意开头必须要是 ^字符串开头 比如这里是^Hello 结尾是 字符串结尾$ 比如这里是Demo$. 记得先导包,import re.
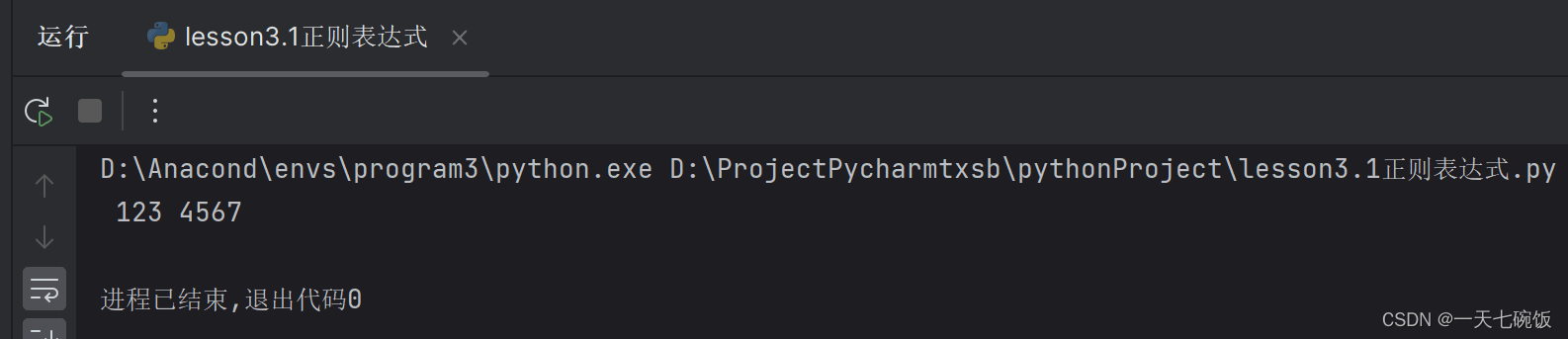
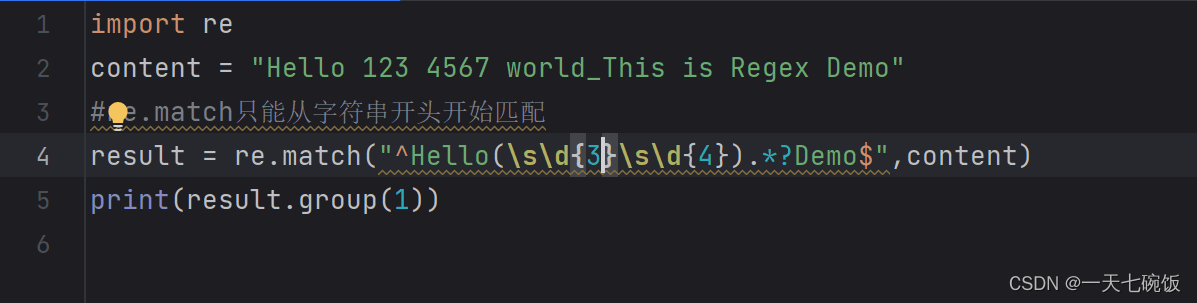
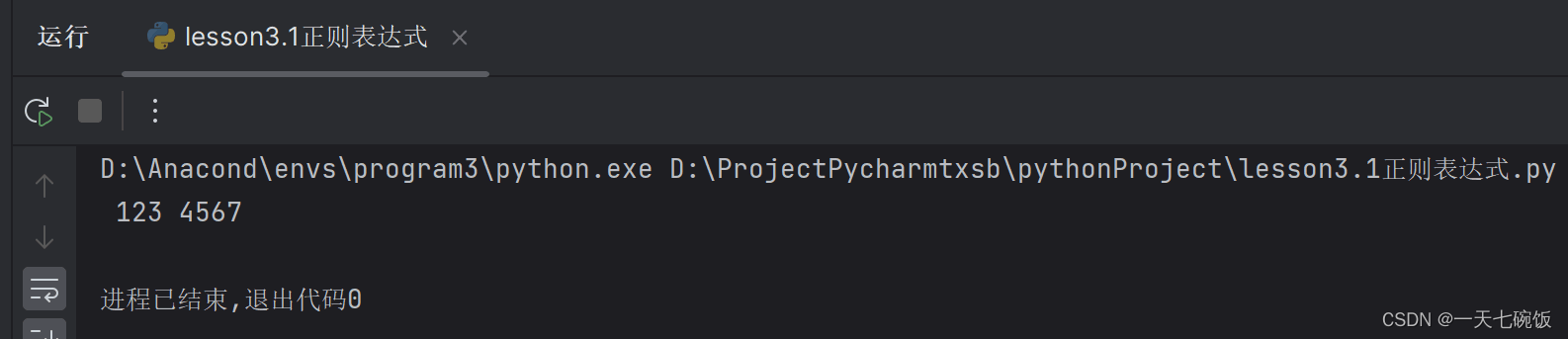
当我们只要运行结果 123 4567 的时候(注意有空格),我们去元字符中寻找可以表示空格和数字的字符,我们可以知道是 \s 和 \d 。那我们按照顺序一个一个对应输上去就是\s\d\d\d\s\d\d\d\d。这里要注意你要得到哪个结果就要框哪个表达,具体看图:  3.运行结果 3.运行结果
这里我将我想要运行的语句用括号括起来了,这里只有一句所以只有一句运行语句 print(result.group(1)) 运行结果如下:
当然如果我们要运行获取的结果字符串很多,比如这种情况,当有10位甚至100位呢,我们要输入那么多的字符吗,当然这不现实。所以我们可以在后面直接用 {字符串个数} 来表示。就像这样\d{100} ,这就是有100位数字。话不多说,看图:
最后运行结果是一样的
同样以第一张图为例:
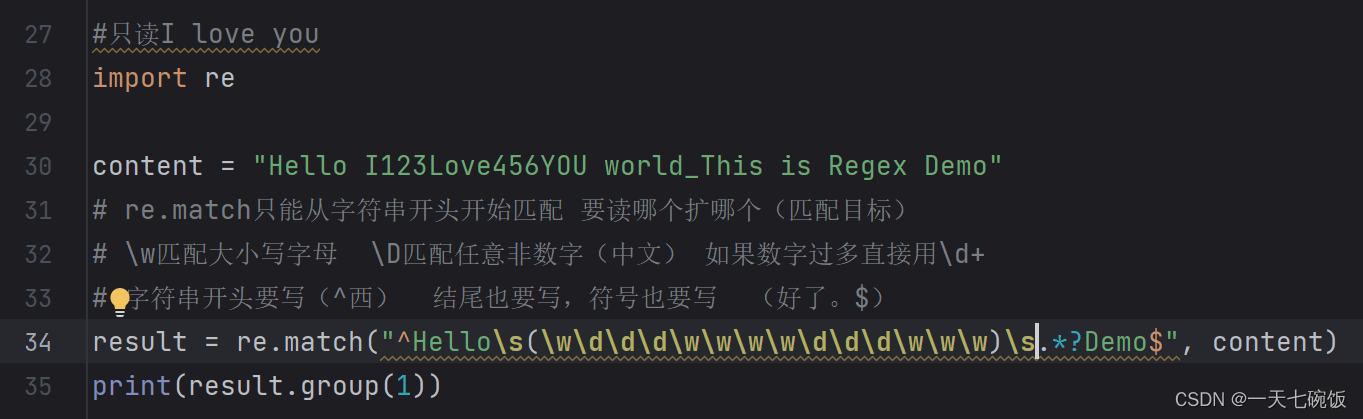
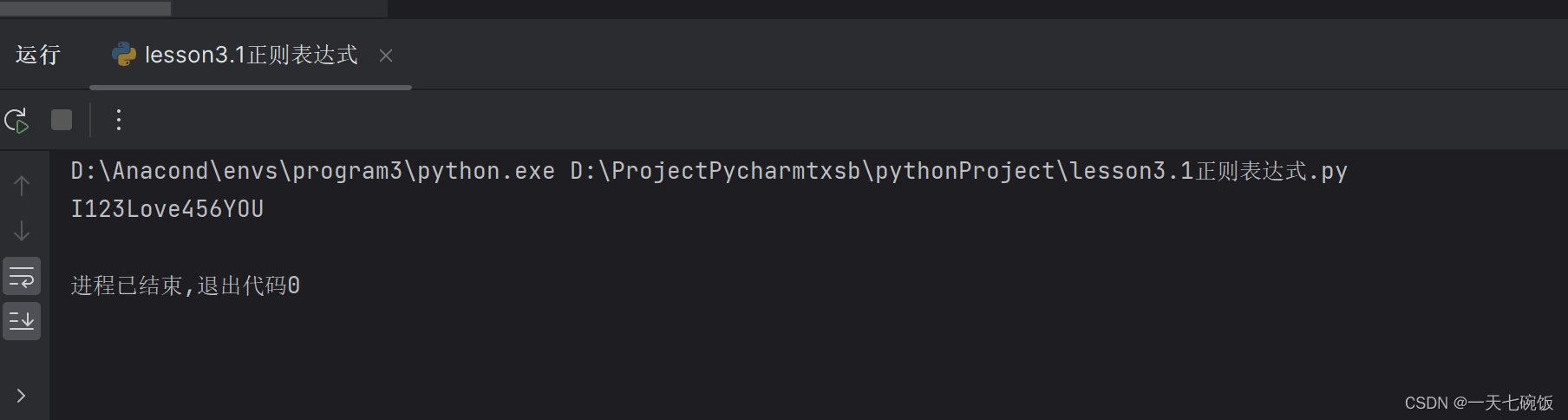
当我们需要得到 I123 Love456YOU 时,就需要输入表示字母与数字的对应字符,我们可以从元字符中找到 \w可以表示字母,从而得到表示我们要得到的运行结果代表队字符。 \s\w\d\d\d\w\w\w\w\d\d\d\w\w\w\s。(这里注意字符前后都是有空格的,一定加上,不然会报错。空格不用括)同样括号括起来。如图:
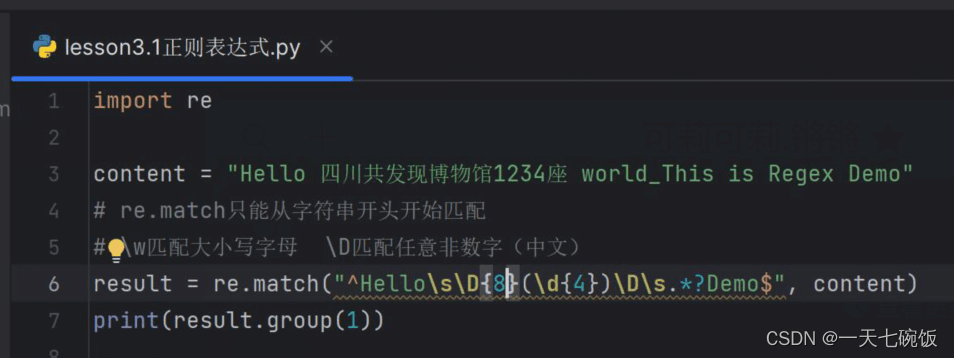
当中文字符与数字相结合,用什么来表示文字呢?查找元字符我们可以知道 \D可以表示中文字符 具体看图:
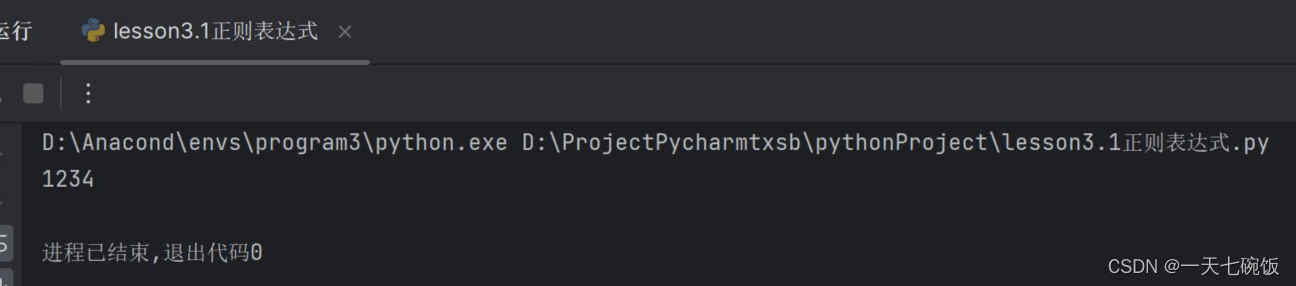
这里我们用刚才上面说的只读数字,可以看到中文字符有8位,所以写下来就是上述情况\s\D\D\D\D\D\D\D\D\D\d\d\d\d\D\s 2.运行结果
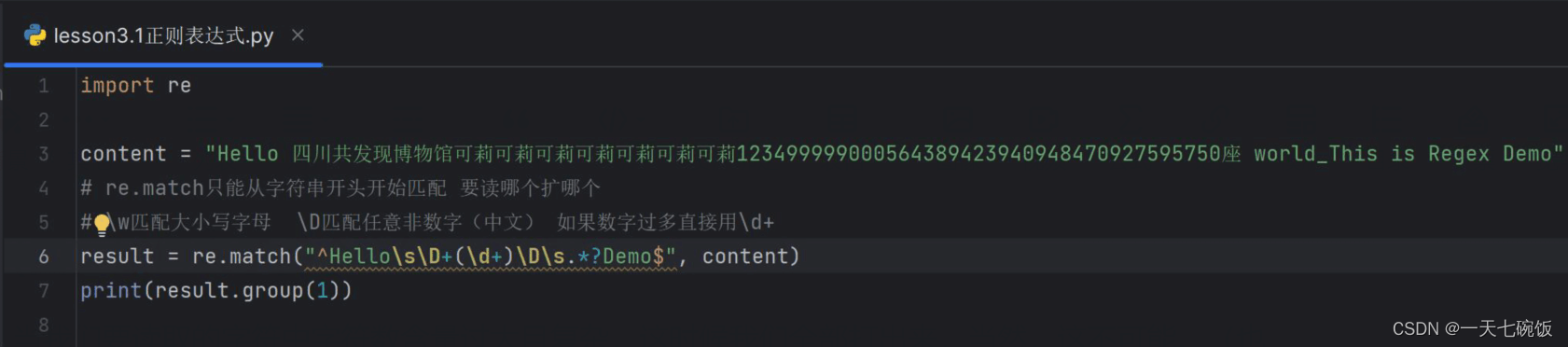
当我们要读取的字符中字符数含量过大且复杂,这时候我们全部打出来,当然,这不可能。(也是可以的,只是时间花费很大)这时候我们可以从元字符中找到一个简便方法 \d+ , \D+.看图:
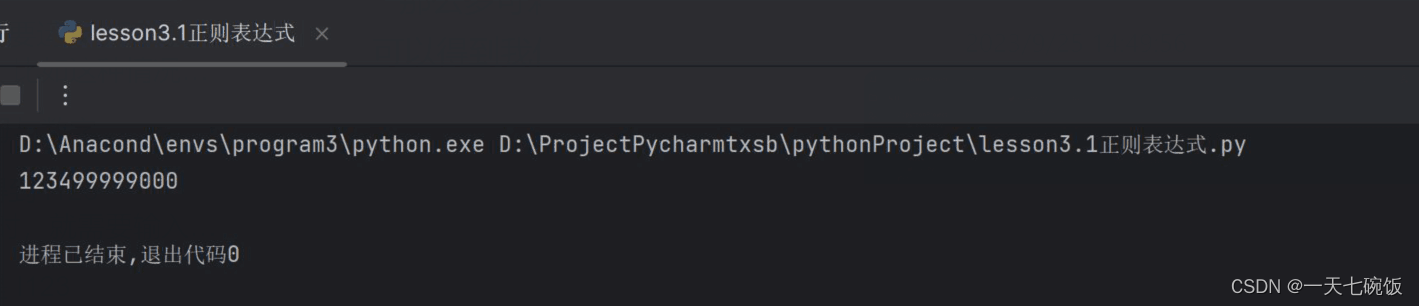
那么多可莉和数字我不可能全打出来,所以用\D+来表示中文字符,\d+来表示数字字符。这样就可以得到我们想要的结果了。
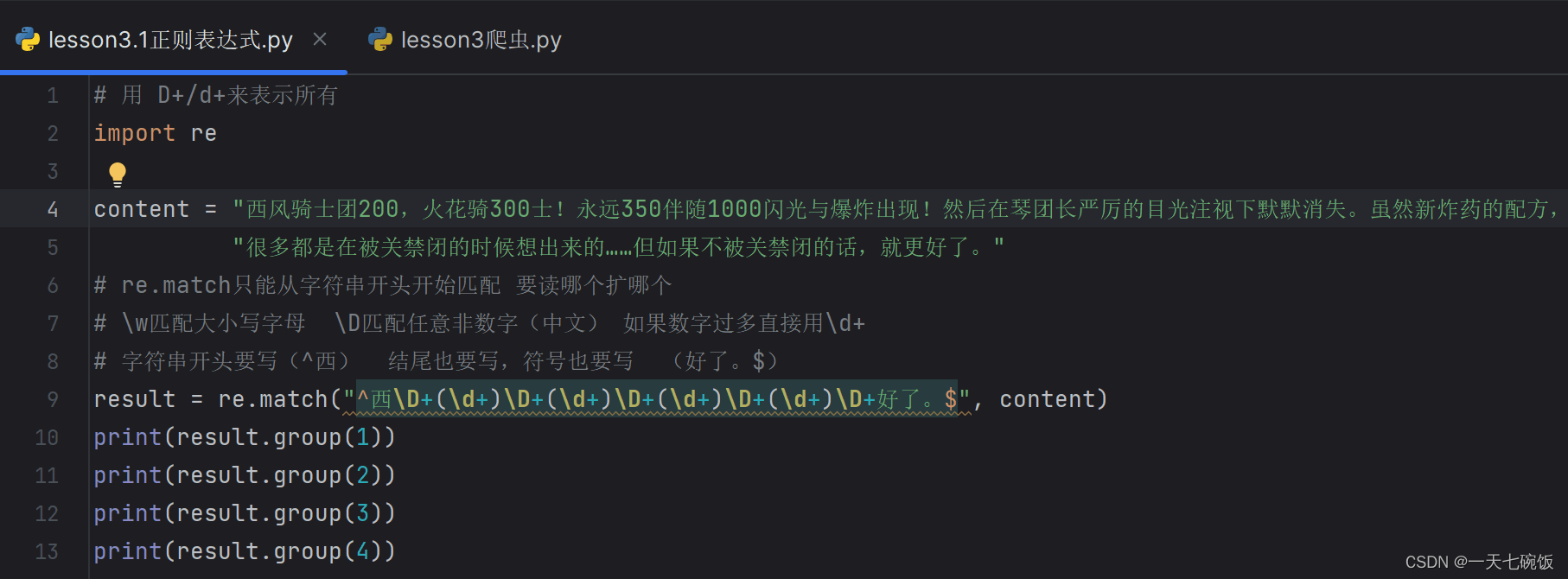
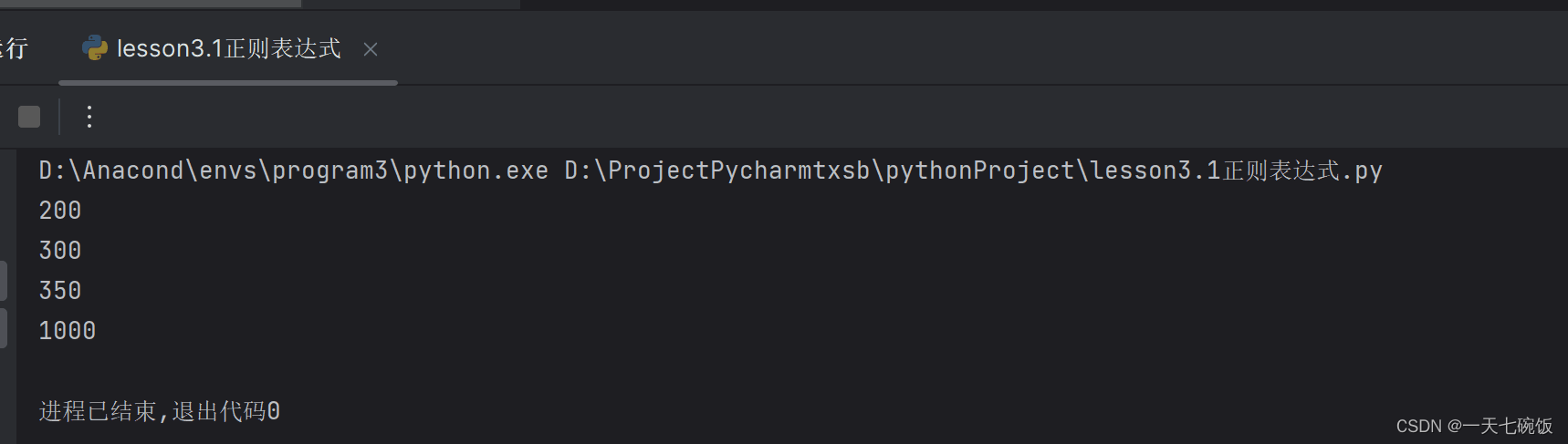
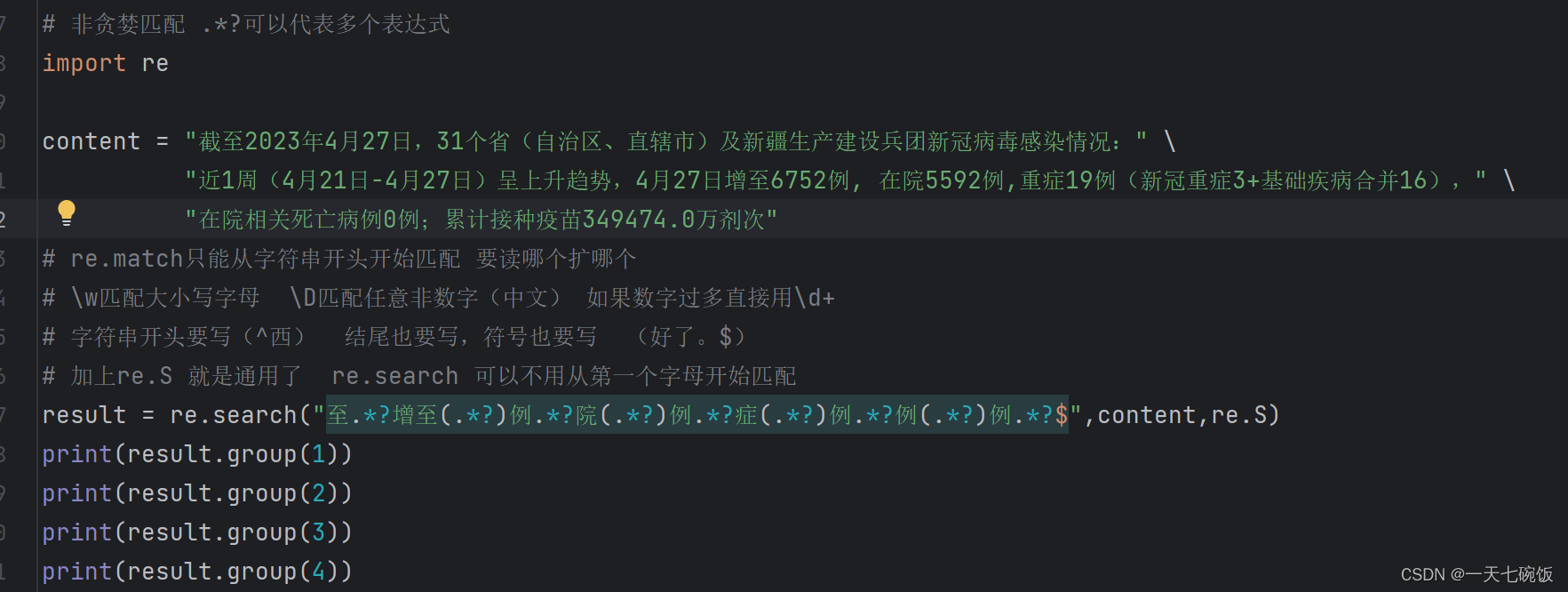
接下来我们看一个结合不规则的情况,前面是中文字符与数字的结合并且文字量很大,这时候我们就可以用刚才讲的\D+ \d+,不过要记得加上开头与结尾。 比如下方的^西 与 好了。$。记得要把输出结果写4遍,因为我们要读4个数字。
这样我们就得到了我们要的数字了。
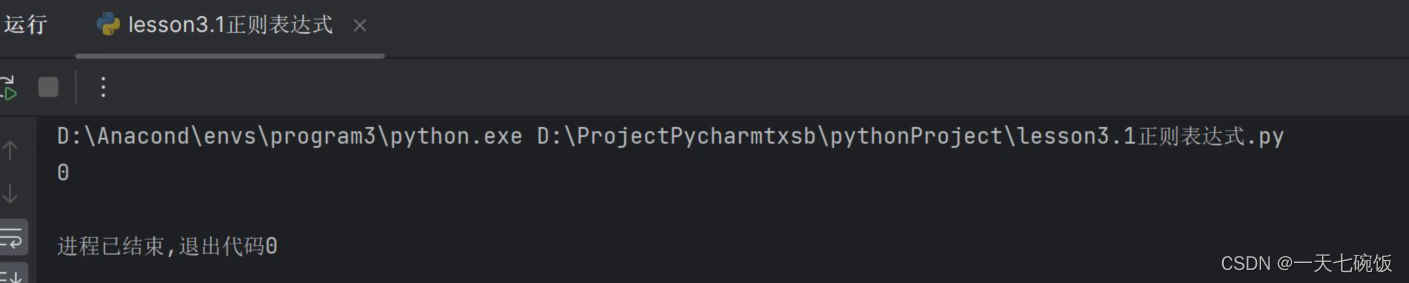
简单介绍一下贪婪匹配: (1)介绍在贪婪模式下,匹配器尽可能多地匹配符合要求的字符,直到不能再匹配为止。例如,正则表达式 a.*b 在匹配字符串 "abbcab" 时,会匹配整个字符串 "abbcab",而不是期望的 "ab"。 (2)用例我们看个例子。我们想要读取数字200,而我们用贪婪匹配就是用 .* 来表达我们所有的字符中间的数字字符用\d+表示。 前面说了那么多的元字符,归根结底就是三个字符 .*?它可以代表所有的字符
让我们看看运行结果吧,只有一个0.这就是贪婪匹配,只有
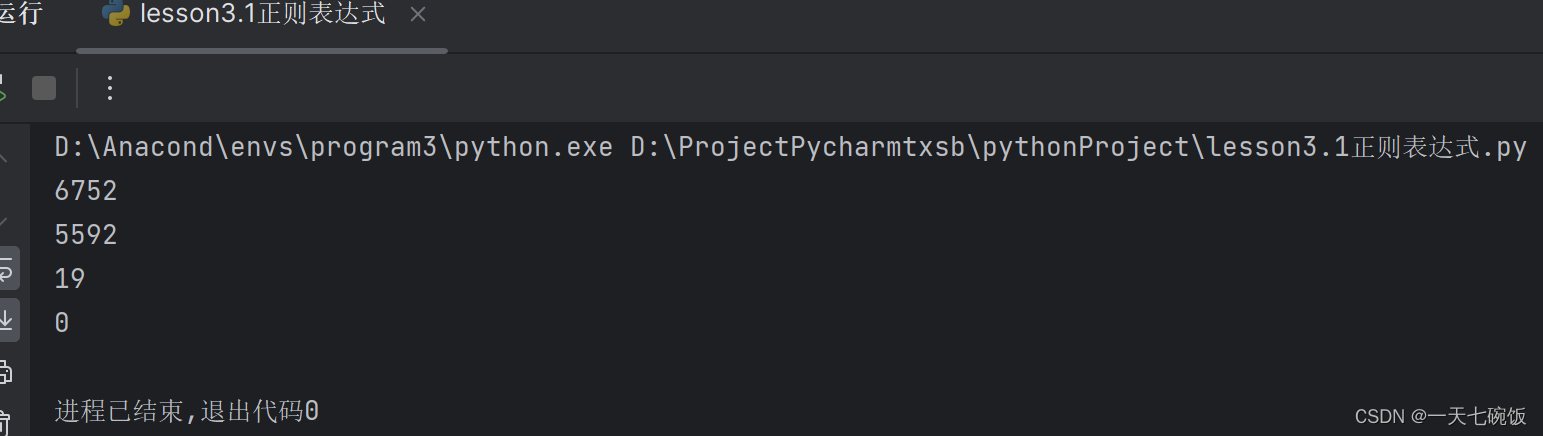
在非贪婪模式下,匹配器尽可能少地匹配符合要求的字符,直到满足要求为止。例如,正则表达式 a.*?b 在匹配字符串 "abbcab" 时,只会匹配到第一个 "ab",而不是整个字符串。 看个例子:用.*?表示字符,主要结尾加上re.S
运行结果:
(2) 看下面这张图有什么不同吗,我将re.match换成了re.search这样就可以不从第一个字母开始匹配了,得到的结果是一样的。
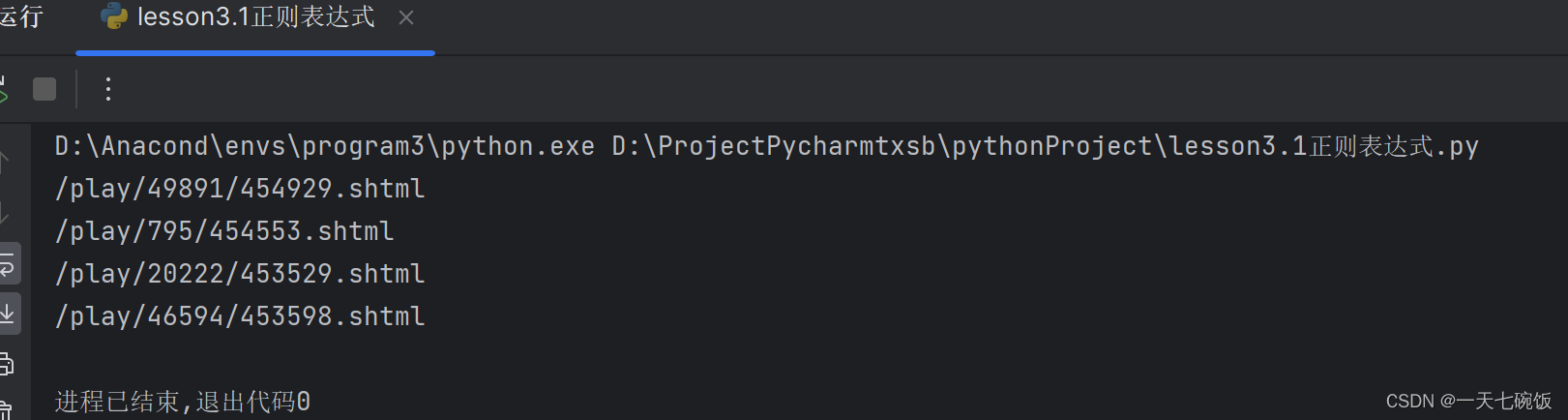
看图: 1.用例从前面的学习中我们可以知道所有的内容都可以用.*?来表示。我们读取href中的内容就简单,记得加上单引号。我们看一句是怎么写的:href="(.*?)" # 提取html中的 import re content = """ 1亲爱的小课桌 2悟空 3粉雾海 4姐真漂亮 5斯芬克斯 """ # re.match只能从字符串开头开始匹配 要读哪个扩哪个 # \w匹配大小写字母 \D匹配任意非数字(中文) 如果数字过多直接用\d+ # 字符串开头要写(^西) 结尾也要写,符号也要写 (好了。$) # 加上re.S 就是通用了 re.search 可以不用从第一个字母开始匹配 result = re.search('href="(.*?)".*?href="(.*?)".*?href="(.*?)".*?href="(.*?)"',content,re.S) print(result.group(1)) print(result.group(2)) print(result.group(3)) print(result.group(4)) 结果:
让我们来看另一种写法,用findall,直接输出结果 #findall 可以获取所有的数据 import re content = """ 1亲爱的小课桌 2悟空 3粉雾海 4姐真漂亮 5斯芬克斯 """ # re.match只能从字符串开头开始匹配 要读哪个扩哪个 # \w匹配大小写字母 \D匹配任意非数字(中文) 如果数字过多直接用\d+ # 字符串开头要写(^西) 结尾也要写,符号也要写 (好了。$) # 加上re.S 就是通用了 re.search 可以不用从第一个字母开始匹配 result = re.findall('href="(.*?)"', content, re.S) print(result) 结果:
好了这次的正则表达式示例详解就说完啦,感谢观看。 |



【本文地址】